今天用 dataviewjs 配合 [[obsidian-components|components]] 、[[obsidian-Thino|Thino]] 实现了一个复杂的功能:在 thino 即每日日记中输入 dataview 双冒号格式的模板,如知识卡片模板,自我觉察模板等,可以通过该段代码自动聚合带有相应标签的模板,并形成表格。
总结即:只在日记记录、thino 快捷入口、一套代码复用无需更改。
效果如下:
- 在 thino 中输入任意 dataview 格式的内容和相应标签,如这里写两条不同标签的内容
- 在配置好的 component 里选择相应标签,效果如下:
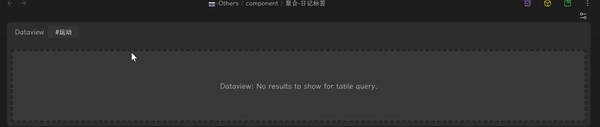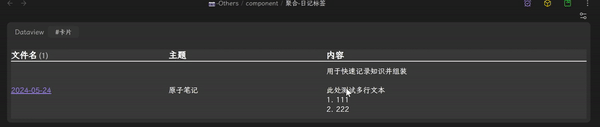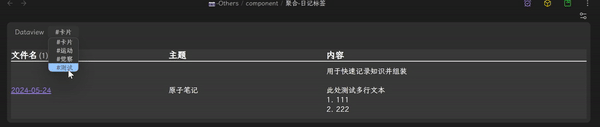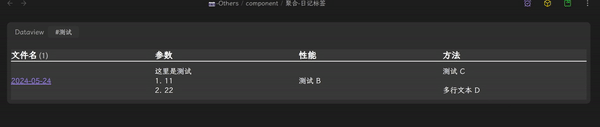
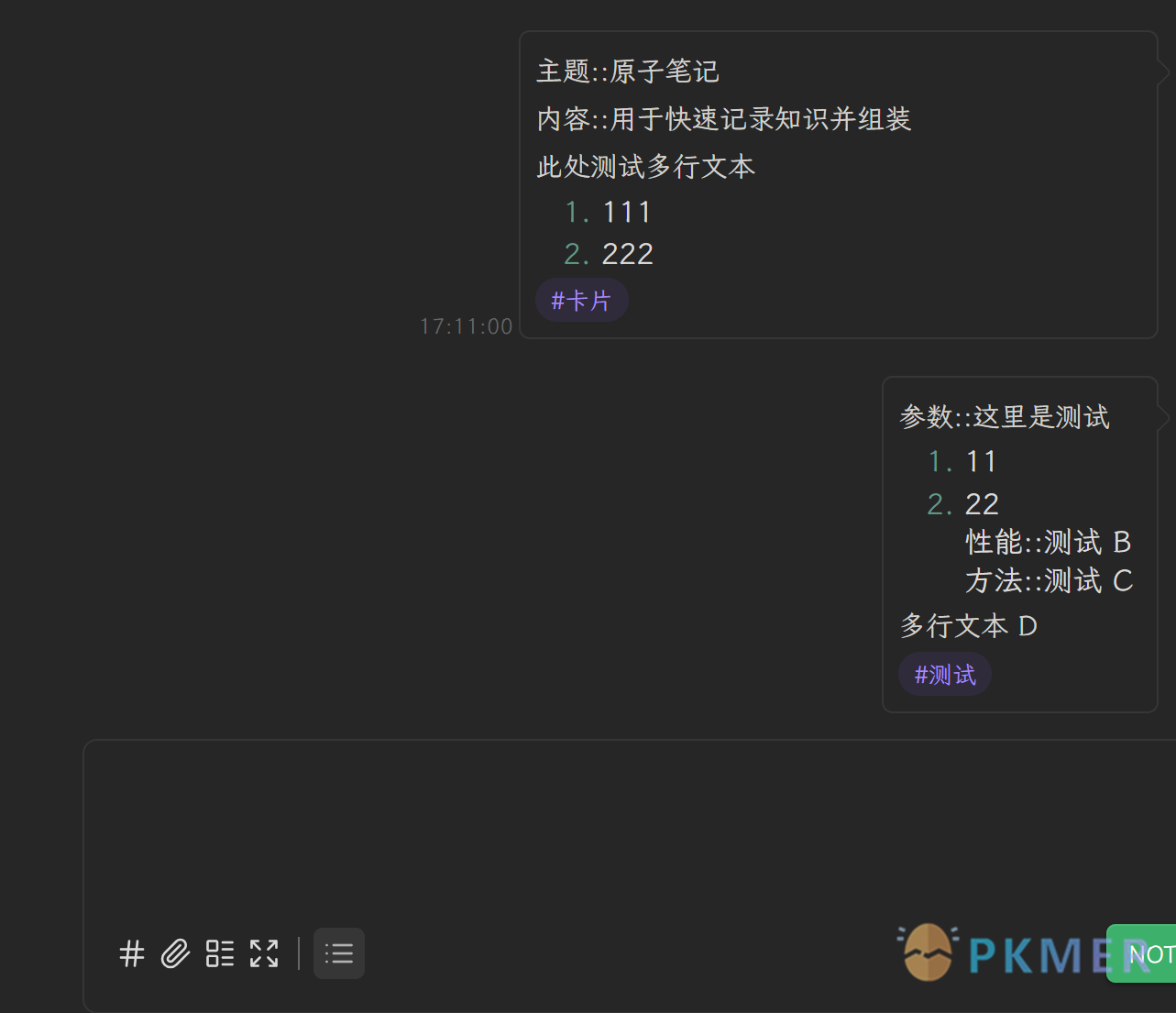
这种好处非常多:
- 不需要使用多文件模式区分各种原子笔记,觉察笔记了,直接全部放到每日日记里,这样也能很好的行使记录和成长型功能。日记成为了所有事物的第一入口。
- 一份代码完成所有聚合。不需要再去写各种表头了,它会自动寻找该标签的单次消息中的 dataview 元数据,并自动形成表头。
- dataview 的内联元数据实际上是不支持多行文本的,这大大限制了内容的攥写,比如列表、空行等等。但是这个代码会自动识别这种元数据和对应的块内容,不需要多文件模式也可以很好的记录了。
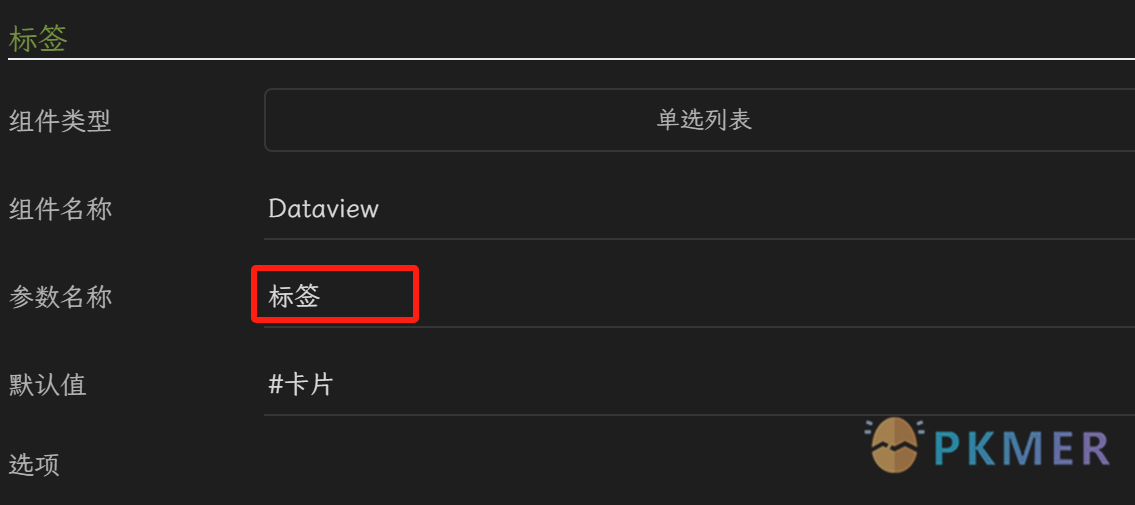
- 不需要更改代码:通过结合 component 插件中的 dataviewjs 动态参数模式,将标签动态化,使得代码无需改动可以适配于任意标签模板。直接拖拽到页面即可,非常方便。
配置
-
component 设置:组件 -dataview-dataviewjs
-
代码如下(注意修改指定日记文件夹、thino 对应的日记章节):
const folderPath = "1-DailyNote"; // 指定日记文件夹路径
const tag = "{{标签}}"; // 指定标签
const files = dv.pages(`"${folderPath}"`);
let results = [];
async function processFiles() {
for (let page of files) {
if (!page.file.tags || !page.file.tags.includes(tag)) {
continue;
}
const file = app.vault.getAbstractFileByPath(page.file.path);
if (!file) {
console.error(`找不到文件: ${page.file.path}`);
continue;
}
let content;
try {
content = await app.vault.read(file);
} catch (error) {
console.error(`读取文件 ${page.file.name} 时出错:`, error);
continue;
}
let memosRegex = /## Memos\s*([\s\S]*?)(?=\n##|\n$)/g; # //这里修改对应的thino section,我是## Memos
let memosMatch = memosRegex.exec(content);
if (!memosMatch) {
continue;
}
let memosContent = memosMatch[1].trim();
memosContent += '\n';
let timeBlockRegex = /- (\d{2}:\d{2})\s+([\s\S]*?)(?=\n- \d{2}:\d{2}|\n$)/gm;
let timeBlockMatch;
while ((timeBlockMatch = timeBlockRegex.exec(memosContent)) !== null) {
let time = timeBlockMatch[1].trim();
let blockContent = timeBlockMatch[2].trim();
if (blockContent.includes("[archived::true]")) {
continue;
}
if (!blockContent.includes(tag)) {
continue;
}
blockContent = blockContent.replace(new RegExp(tag, 'g'), '').trim();
blockContent += '\n';
let subRegex = /^\s*(?!\[)(\S+?)::\s*([\s\S]*?)(?=\n\s*\S+?::|\[webId\S*\]|\n$|\n- \d{2}:\d{2})/gm;
let subMatch;
let row = { "文件名": dv.fileLink(page.file.path, false) };
while ((subMatch = subRegex.exec(blockContent)) !== null) {
let key = subMatch[1].trim();
let value = subMatch[2].trim();
// 去掉正文中的 [webId::…] 部分
value = value.replace(/\[webId::\d+\]/g, '').trim();
row[key] = value;
}
if (Object.keys(row).length > 1) {
results.push(row);
}
}
}
let columns = new Set();
results.forEach(row => Object.keys(row).forEach(key => columns.add(key)));
let tableData = results.map(row => Array.from(columns).map(col => row[col] || ""));
dv.table(Array.from(columns), tableData);
}
processFiles();