这是一篇小白写给小白的,关于实现本地大语言模型接入obsidian的教程,共包含6个部分,分别是:
- 概念界定
- 教程的由来
- ollama配置
- copilot插件配置
- 杂谈
- 结语
其中3、4、5部分为正文,全文共计3154个字。
一、概念界定
Obsidian(哦波C点):
中文名叫黑曜石,是一款笔记管理软件,允许用户创建、链接和组织笔记,帮助用户构建知识网络,促进信息的整合和创新思考。
本地大语言模型(Large Language Model ,简称LLM):
本地大语言模型可以简单理解为,在自己电脑上运行的,不需要联网就能使用的 AI。大语言模型可以处理多种自然语言任务,如文本分类、问答、对话等。本地大模型的优点是免费,不用担心隐私泄露问题。正文部分将其简称为大模型。
Ollama(欧拉玛):
Ollama 是一个在本地环境中运行和管理大型语言模型的工具。用户可以通过 Ollama平台将开源大模型下载到自己的电脑上,执行各种任务。Ollama 平台的目标是让非技术用户(比如我)也能轻松地利用 AI 来增强工作流程和创造力。
二、教程的由来
大约一个半月前,我萌生了一个创新想法:将人工智能(AI)与Obsidian这样的知识管理软件相结合,可能会产生意想不到的效果。Obsidian以其强大的笔记关联和知识整理能力而著称,能够将零散的信息整合成系统化的知识体系,并且方便用户随时调用和查询。
想象一下,如果我们能够在个人电脑上部署一个AI模型,让它深度学习整个Obsidian知识库的内容,这样的AI将能够更深入地理解笔记之间的联系,提供更加精准的信息检索和整合建议,甚至能够主动提出笔记间的潜在联系和知识扩展点。
如此,Obsidian将不仅仅是一个知识管理工具,而是成为用户真正的"第二大脑",在知识调用、问题解答和内容整合方面提供更加智能和个性化的服务。这将极大地提升我们的工作效率,帮助我们更好地管理和利用个人知识库。
经过不断尝试,我终于找到了一种既简单易用又可复制的方法,可以将本地大型语言模型轻松接入Obsidian。这一发现促使我撰写了这篇教程,旨在分享本地大模型在 Obsidian 中的妙用。
本教程正文分为三个部分,第一部分是从 Ollama 网站下载大模型,然后在自己的电脑上运行(简单,难度![]()
![]() );第二部分是借助 Copilot 插件,把本地大语言模型接入 Obsidian 知识库,打造自己的第二大脑(有点复杂,难度
);第二部分是借助 Copilot 插件,把本地大语言模型接入 Obsidian 知识库,打造自己的第二大脑(有点复杂,难度![]()
![]()
![]() )。第三部分是杂谈,主要讲讲自己看过的视频教程,以及踩过的一些坑。
)。第三部分是杂谈,主要讲讲自己看过的视频教程,以及踩过的一些坑。
三、Ollama 配置
-
首先打开Ollama 官网 (https://Ollama.com/),下载安装包然后安装。
-
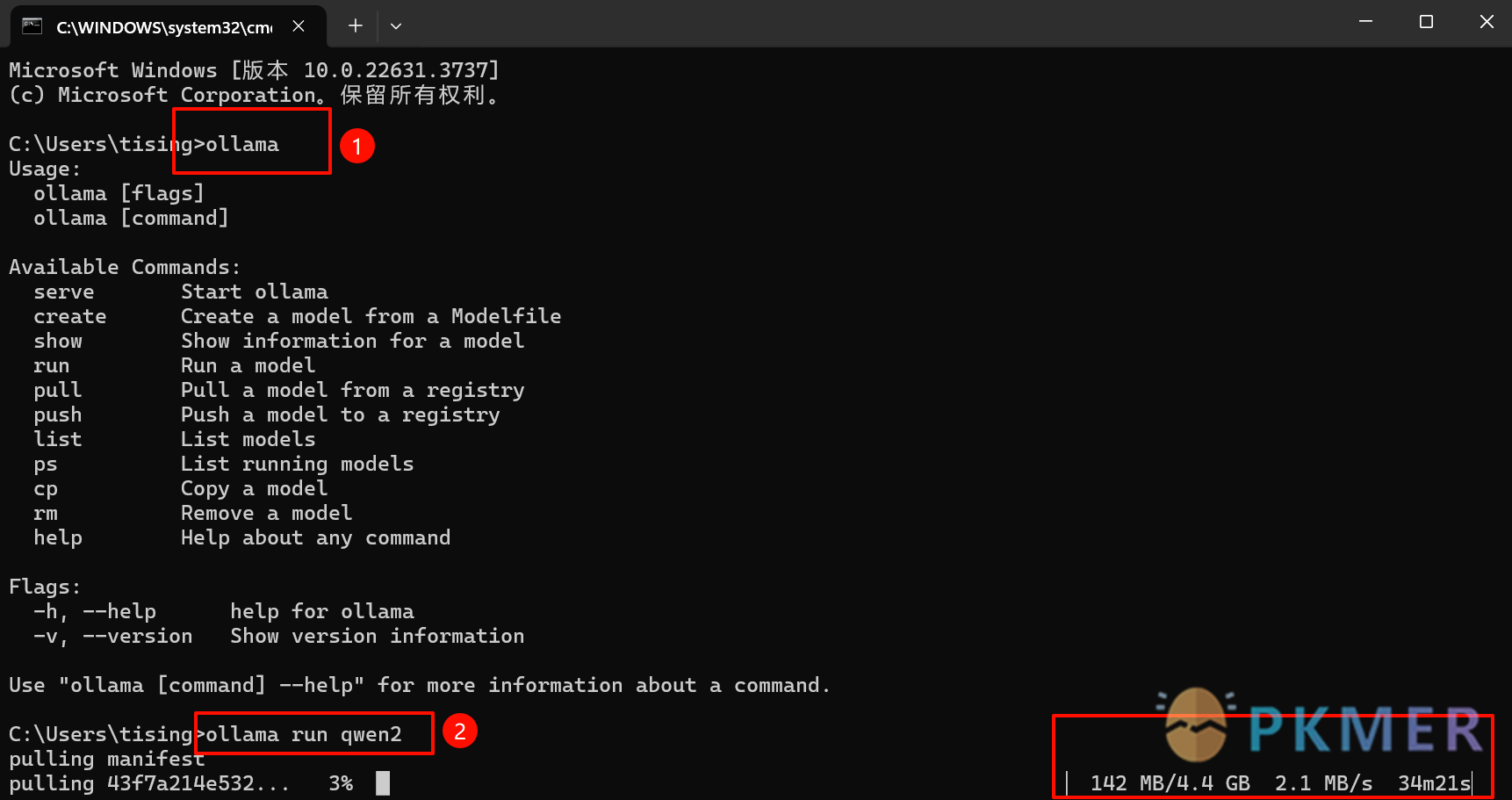
其次 Windows 电脑按住 win+r 键,输入 cmd 点确定,调出命令行,在命令行输入 ollama 后按 enter 键,能看到 Ollama 的安装信息(如图 1 所示)。
图1 ollama命令行界面 -
在 Ollama 官网界面右上角搜索框输入 qwen 2(阿里通义千问的最新开源版,超级好用),点 view all,选择 qwen 2 的 7 b 模型后(如图2所示),复制
ollama run qwen 2
粘贴在刚才的命令行中,按 enter 键运行,自动开始下载qwen 2的7 b 模型(如图 1下红框处所示)。
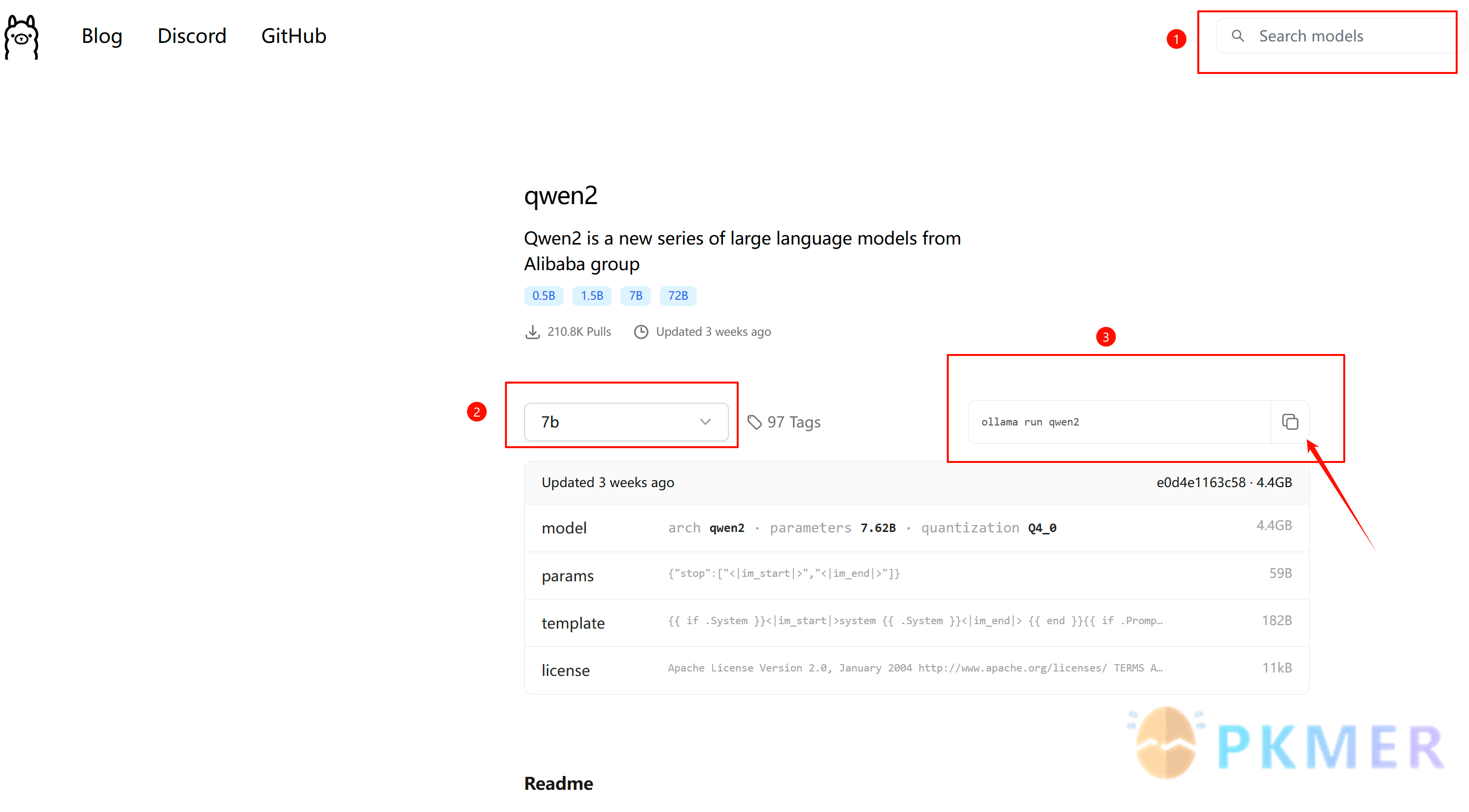
图2 ollama官网界面
-
下载进度条跑到 100%后,下面会出现 send a message,此时就可以在命令行中与本地大模型进行对话啦(是不是很简单)。
-
关掉命令行和电脑右下角的骆驼图标后,再次启用大模型还是按照上面的步骤打开命令行,输入 ollama run qwen 2 运行即可。
看着有点晕没关系,文章最后有视频教程
四、Copilot 插件设置
-
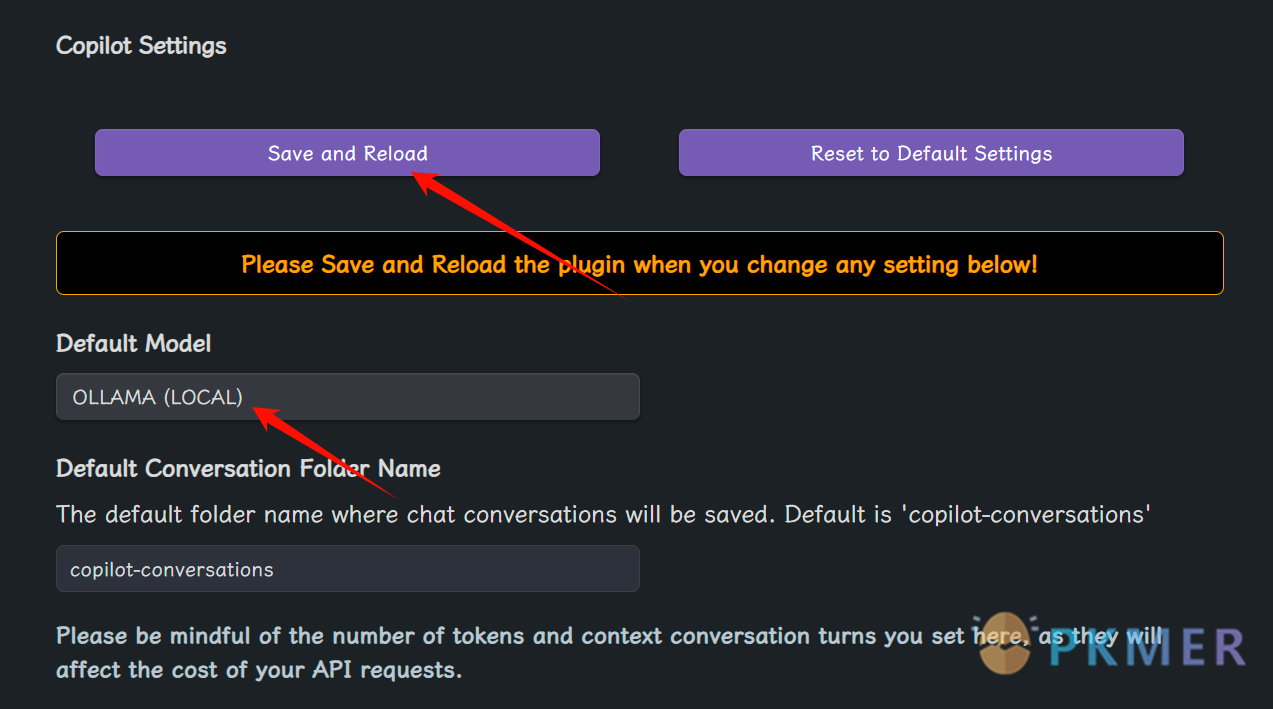
在 Obsidian 中下载 Copilot 插件并进入设置界面,设置界面最上方有 save and reload 按钮,每次修改完插件设置都要点一下保存修改内容;还要将“Default Model”改成 Ollama (LOCAL)
图3 copilot插件设置01 -
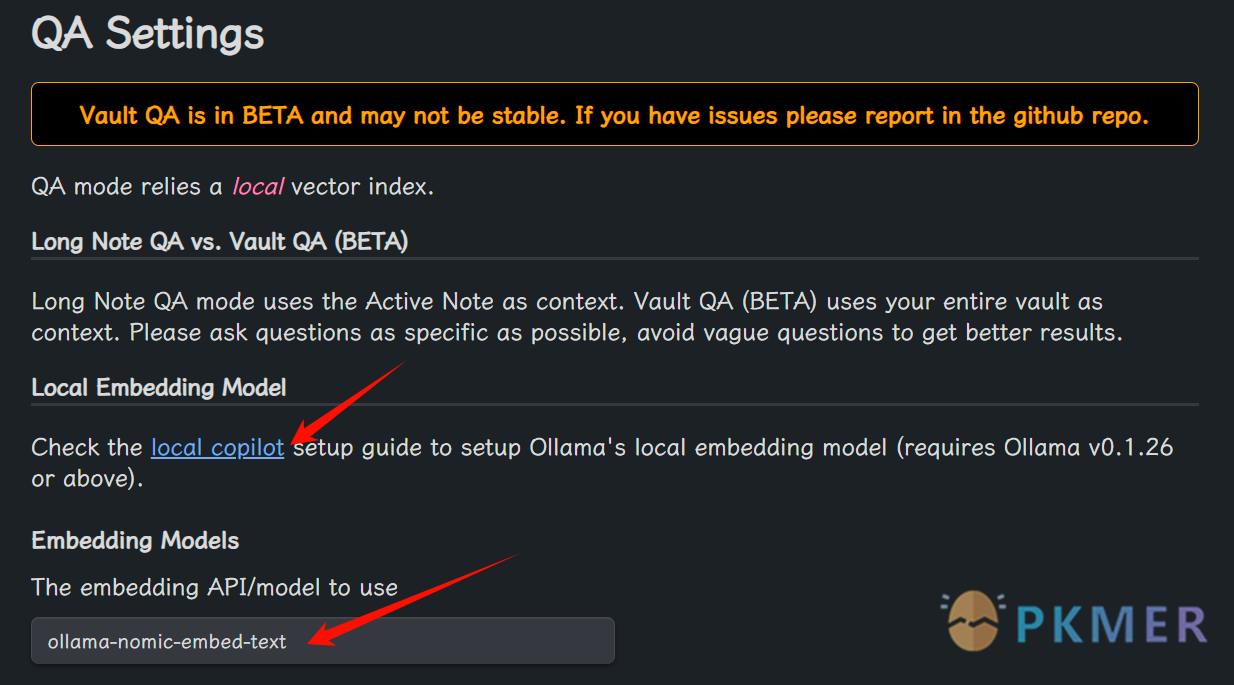
将QA Settings 下面的Embedding Models 选项改成 Ollama-nomic-embed-text(很重要!) Embedding Models 上面有个蓝色的 local Copilot 链接,是插件作者写的插件设置注意事项,可以点开看看。
图4 copilot插件设置02 -
将Auto-Index Strategy 下面的Auto-index vault strategy 改成 ON MODE SWITCH。
-
找到 Local Copilot (No Internet Required!) 下面的 Ollama model 改为 qwen 2。
Copilot 插件的设置大概就是这些,没提到的地方不用动。
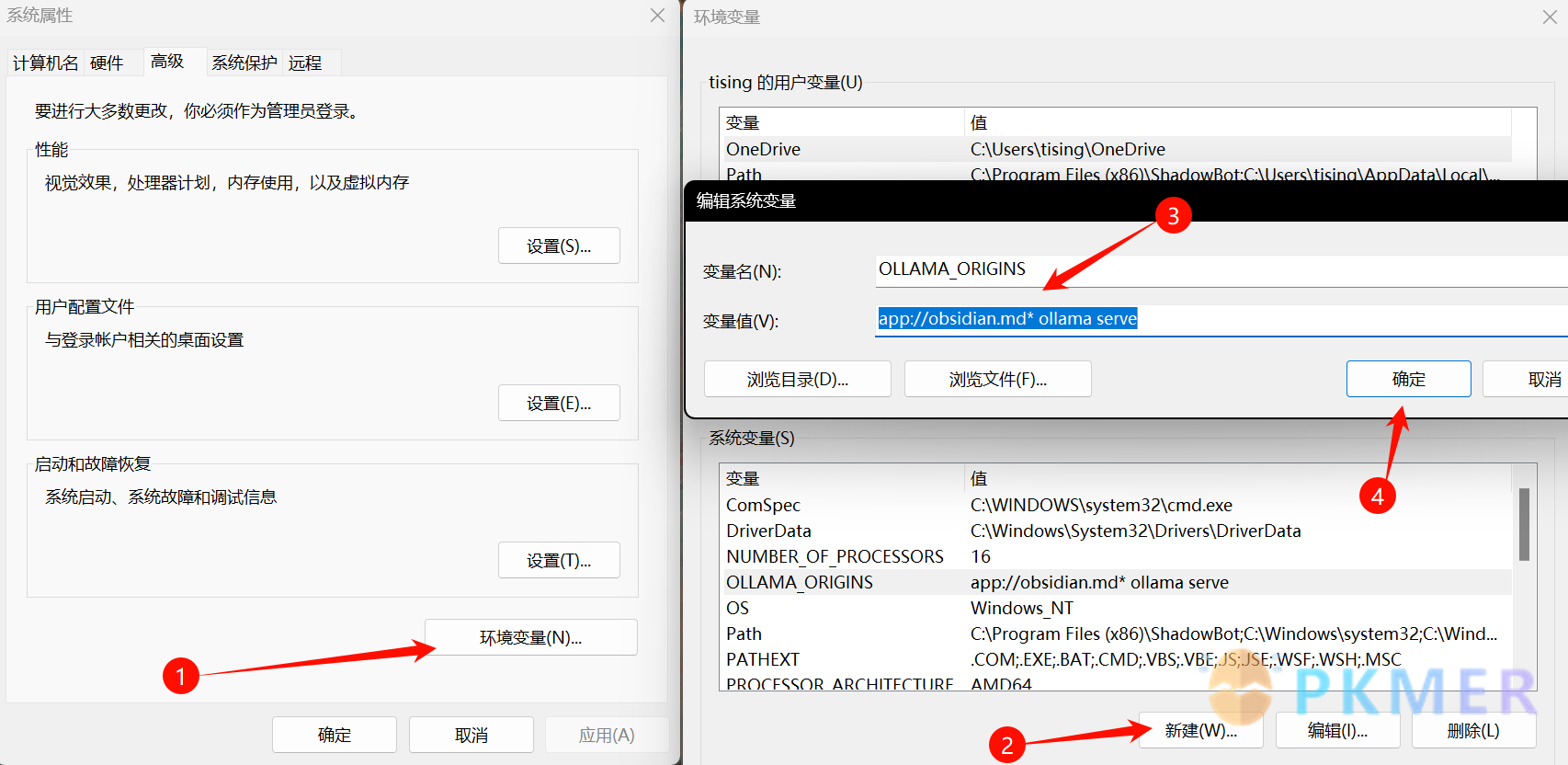
想要让 Ollama 跟 Copilot 联动,还需要在电脑上配置环境变量,具体做法:
-
在电脑设置中搜索并打开编辑系统环境变量。
-
点击右下角环境变量-系统变量-新建,变量名填 OLLAMA_ORIGINS,变量值填 app://obsidian. md* ollama serve,填完之后点确定保存即可(如图 5 所示)。
图5 系统新建环境变量
一切准备就绪,可以开始用起来啦!
- 首次使用要先打开命令行,输入
ollama pull nomic-embed-text
然后运行,这是对整个知识库进行向量化(非常重要!)。
- 向量化完成,命令行输入
ollama run qwen 2
开始运行 qwen 2模型。
- 重启 Obsidian,在左侧边栏找到 Copilot chat 按钮并点击,即可在右侧边栏开始对话(如图 6 所示)。
图6 copilot聊天界面
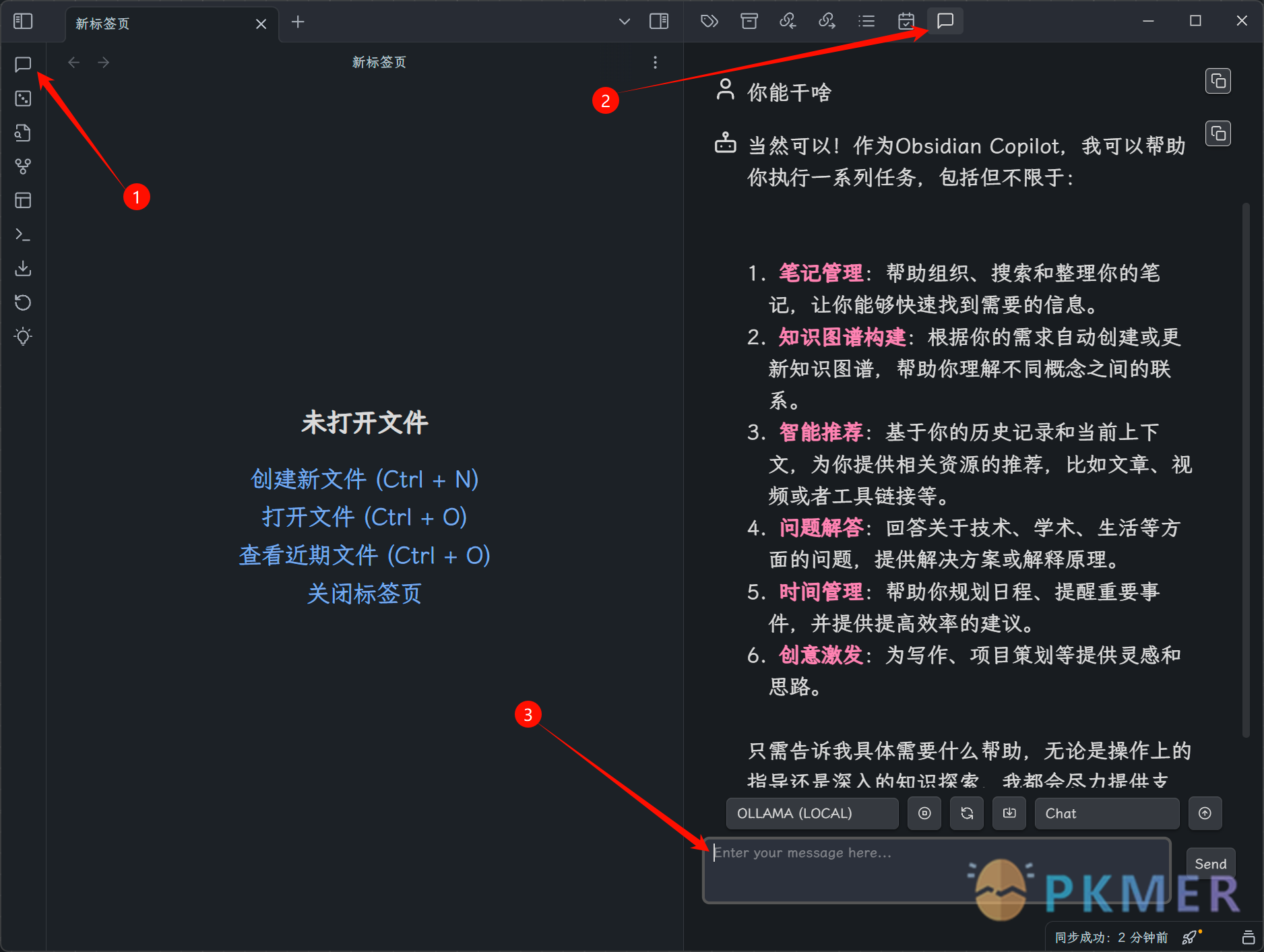
默认的是 chat 模式,在输入框输入两个英文的方括号,就能链接到库中的任意笔记,可以让它分析总结某篇或者某几篇笔记的内容。
问法示例:帮我总结 [[本地大语言模型接入Obsidian,打造专属第二大脑!]]这篇笔记的核心内容。
打开Obsidian 命令面板,输入 Copilot 能看到很多关于 Copilot 插件的命令,这里主要强调两个命令:
Copilot: Force re-index vault for QA 命令,是强制让整个知识库向量化,建议首次使用先运行这个命令,右上角应该会出现图 7 的通知。
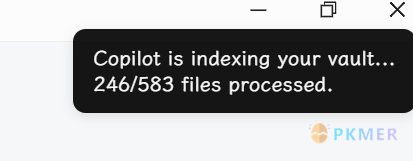
图7 知识库强制索引通知
Copilot: Set note context for Chat mode 命令,能够选择让大模型只读取某个文件夹中的内容,设置好要读取的文件夹并submit,再点击 chat 按钮右侧的那个箭头按钮就能把此文件夹中的笔记都发送给大模型进行读取(如图 8 所示)。
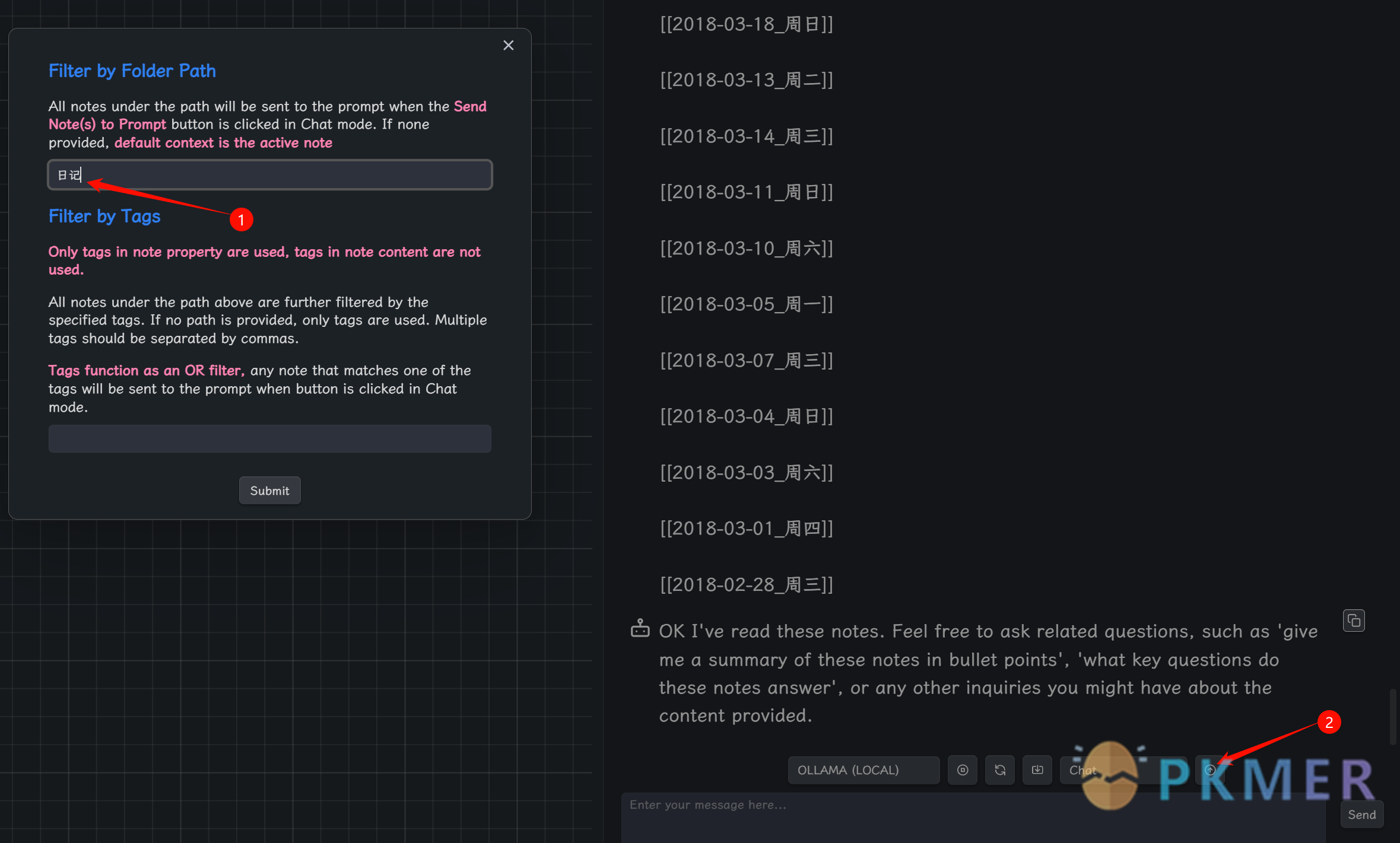
图8 发送文件夹内笔记给大模型
我选择了日记库中近六年的几百篇日记给它读,回答效果不太理想。原因大概有以下两点:
-
当前开源大模型的能力还有待提升,几百篇日记的文本量还是有点大,或许换成 110 b 的模型才能真的读懂我(家人们谁懂啊)。
-
Copilot 插件本身的库问答功能做得还不太行,后期可以试试 Obsidian 的其他 ai 插件,比如 smart second brain、smart connections、text generator、omnivore 等。
其他有趣的玩法和更详细的操作,在文章最后的视频教程中都会提及,这里就不再赘述。
五、杂谈
详细操作可以借鉴的B站视频教程:
【1700 多种开源大模型随意部署!一键本地搭建大模型+知识库,不挑环境、不挑配置】
这个教程主要讲 Ollama 的配置,看前半部分即可,后面的安装docker 又是另一个大坑,很麻烦。
【王炸![]()
![]()
![]() Obsidian 加上本地部署 AI 大模型!】
Obsidian 加上本地部署 AI 大模型!】
这个教程主要讲 Copilot 插件配置和使用,除了“首次使用要运行Ollama pull nomic-embed-text ”的操作没讲,其他都很详细。
其实我之前就做过尝试,虽然成功了但是效果很差而且不好复刻。一开始我选择了 LM STUDIO 这个软件运行开源大模型,优点是有很漂亮的操作界面,操作性和美观性吊打 Ollama 的命令窗口。
但是由于极难解决的网络问题,LM STUDIO 不能正常从 huggingface 平台(另一个开源大模型整合平台)搜索和下载大模型,我试了很多方法都下载不了。比如我尝试用 vs code 软件把 LM STUDIO 配置文件夹中的 huggingface 域名都替换成国内的镜像网站,结果只是能在 LM STUDIO 中搜到大模型,依旧无法下载。
最后我在其他地方下载了别人搬运的 llama 3的7 b 模型,放在 LM STUDIO 里面跑,然后再用 Copilot 插件接入 Obsidian,勉强能聊天,但是因为不知道怎么把整个知识库向量化,导致库问答功能(Vault QA)无法使用。而且搬运的 llama 3模型不仅体积大(8 G 多),响应速度也很慢。外加最近一直在忙着改论文和毕业的事情,于是本地大模型接入 Obsidian 这个项目就被我一直搁置。直到昨天尝试了 Ollama 平台,才达到预期效果。
当然,每个人的电脑配置不同,操作过程中遇到的问题肯定也不同,难免会出现各种各样千奇百怪的bug,但只要能把模型跑起来,就算成功。大致的实现思路就是教程里写的这样,如果有问题欢迎在评论区留言,本人对教程的有效性不做保证(实在是被各种排障搞怕了)。
六、结语
尽管这篇教程篇幅较长,我依然很想分享给大家。我认为人工智能(AI)的出现及其广泛应用,是人类历史上的一个重大转折点,它标志着继蒸汽时代和电气时代之后的又一个全新工业时代的到来。AI技术以其卓越的数据处理能力、精准的模式识别和高效的自动化决策,正在深刻地重塑我们的工作、生活乃至思维模式。
了解并应用AI,对于我们每个人来说都至关重要。这不仅能够帮助我们更好地适应技术发展带来的变革,更能让我们在时代潮流中保持竞争力和创新力。
对本地大模型感兴趣的朋友们可以找个小模型在自己电脑上跑一下,喜欢折腾Obsidian 的朋友们可以设置好 Copilot 插件把大模型接入 Obsidian。如果不想折腾也没事,至少这篇文章看到最后,应该能够了解当前开源大模型是怎么一回事,总归是没有坏处的(没用的知识增加了)。